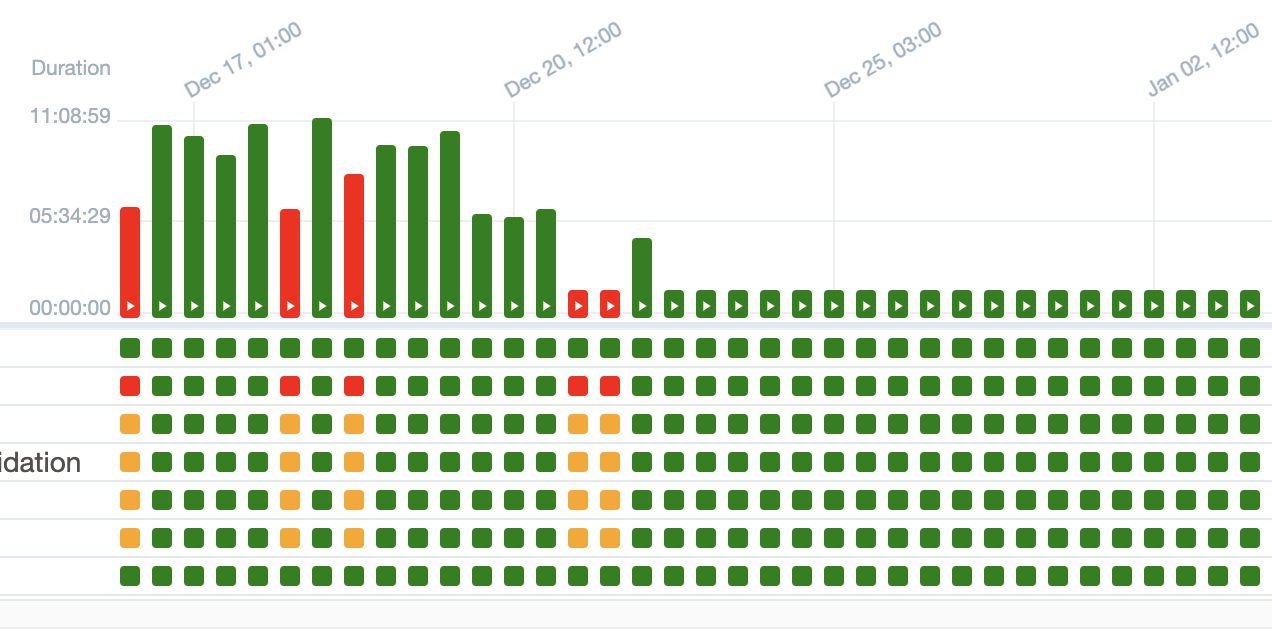
11時間のプロセスを37分に短縮した方法
データエンジニアリングにおけるプロセス最適化
はじめに
この記事は、ウリセスが書いた 5時間のプロセスを5分に短縮した方法 に非常によく似ていますが、文脈が異なります。ここではNodeJSのコードを最適化するのではなく、データエンジニアリングにおけるPythonの適用について扱っており、今回は 11時間かかっていたプロセスを37分に短縮 しました。まずは少し背景を説明させてください。
問題点(冬が来る)
現在、私たちは Apache Airflow というツールを使用してプロセスの自動化を管理しています。これを使うと、crontabでプロセスの実行スケジュールを設定でき、自動的に実行され、Pythonコードで定義されたタスクを実行します。
私たちの多くのプロセスのうちの1つは、プロバイダーからのデータ抽出と、その後ドメインに適応させるための変換です。このプロセスは通常 約5時間 かかっており、いくつかの理由である程度許容できるものでした:
- 通常は夜間に自動で実行され、翌朝には完了している
- 大量のデータを扱うため、すべての操作に時間がかかる
- リアルタイムで必要なわけではないので、他のチームにとっては重要ではない
以下のスクリーンショットは、プロセスが時々失敗することがあるものの、確認と修正で問題なく安定していることを示しています:
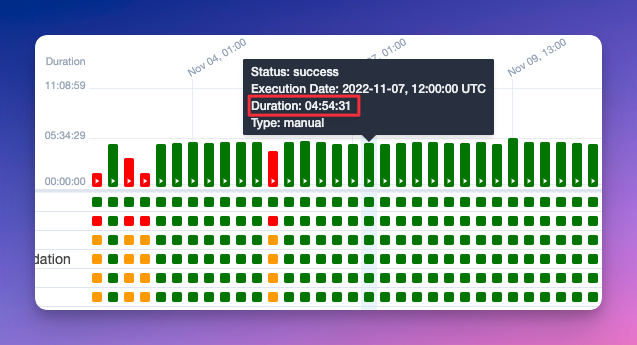
そして冬が到来
何らかの理由で、キューにさらに数百万件のレコードが追加され、実行時間が大幅に増加しました。具体的には、5時間から11時間に増加しました:
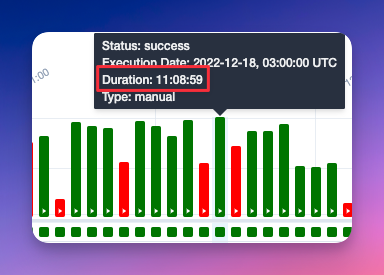
これは管理不可能で持続不可能な状態になっていました。ほぼ半日かかるプロセスが、24時間で2回も実行されるのです…計算してみてください。
なぜこのようなことが起きたのか?
データ処理において定番のライブラリは Pandas で、とてもよく機能します。しかし、大規模なデータセットに対してはパフォーマンスが悪くなります。そこで登場するのが Dask です — 大量のデータを効率的に処理するために設計されています。
Daskは大規模データセットでPandasを上回る性能を発揮しますが、正しく使わないと扱いが難しい場合があります。ベストプラクティスを扱った書籍も多数あり、例えば Data Science at Scale with Python and Dask があります。
そのため、私たちはDaskの使い方に何か問題があるのではないかと考え、コードを見直すことにしました。
謎の謎
まず、プロセスが何をしているのかを確認しました:
3つのデータセットを収集し、1つに統合して、データの出所に基づいた優先リストに従って処理します。これを
provider_rank_listと呼びます(覚えておいてください、後で戻ってきます)。
3つのソースデータセットは単一のファイルではなく、Daskが処理しやすいように分割されています。ここで気づいたのは、その分割が非常に小さいことです — 各1〜2MBの1028パーティション。これはDaskにとって致命的で、すべての利点が逆効果になってしまいます。
私たちが実装した改善の1つは、1028パーティションをより大きなファイルにまとめることでした(ただし、Daskが効率的に動作できるように分割は維持)。
ここで今日の重要なアドバイス:
Daskを使う場合、パーティションはデータ量に合わせて設定してください。あまりにも小さなパーティションが多すぎたり、大きすぎるパーティションが少なすぎたりしないようにしましょう。公式ドキュメントでは 約100MBのパーティション を推奨しています。
考え方を示すコード例は以下の通りです:
input_dataset = dask.read_dask(path_to_file)
dataset_to_process = input_dataset.repartition(partition_size=self._partition_size) # Fix input to ensure it doesn’t break anything
...
Lots of code doing other things...
...
result_dataframe = processed_dataset.repartition(partition_size=self._partition_size) # Fix output size in case it grew during processingなぜファイル数ではなくパーティションサイズを設定するのか?
良い質問です。Daskには2つのパーティション方法があります:npartitions と partition_size。
npartitionsはパーティションの数を正確に固定します。partition_sizeは各パーティションの最大サイズを固定し、Dask DataFrameの処理を強制します。これは一見デメリットのように思えますが、リソースと時間を多く消費するからです。しかし私たちの場合、処理は避けられず、保存時にPandasに変換されるため(DaskはPandasの上に構築されています)。
TL;DR: パーティションの再設定は難しかったので、多くのドキュメントを読み、最適な方法を選びました。
そして…この話はまだ終わっていません :(
パフォーマンスは改善したのでしょうか?はい。完璧だったのでしょうか?いいえ。プロセスはまだ数時間かかり、依然として実用的ではありませんでした。私たちはさらに解決策を探し続ける必要がありました…
そして、次のコード行を発見しました:
dataframe.set_index(provider_priority_column)set_index は何をするのか? -> 指定したパラメータに基づいてDataFrameをソートします。この場合、プロバイダーに基づいてデータをフィルタリングしたいので、いくつかの数値に基づいてソートしたいのです。例えば:
{"cool_provider": 0, "nice_provider": 1, "not_so_cool_provider": 2}以前、この方法を実装したときは、クールで実現可能に見えました…しかし、全くスケーラブルではありませんでした。データ量が増えるにつれて、Daskのソート性能は悪化しました。
ここまで読んだあなたは、非常に複雑な解決策、まるで魔法のレシピのような方法を期待するかもしれません…残念ながら、この解決策はコードとは関係なく、問題へのアプローチの仕方にあります。
解決策
前述の通り、このプロセスは3つのデータセットを取得し、priority_rank_list に基づいてデータを処理するために1つに結合します。私たちは、優先リストに基づいて結合(ほとんど瞬時に行える操作で、ほとんどリソースを消費しません)することを考えました。こうすることで、結果をソートする必要がなくなり、すでにソートされた状態で取得できるため、作業量も大幅に減ります。とてもシンプルです。コードで示すのはあまり意味がありませんが、結果がすべてを物語っています:
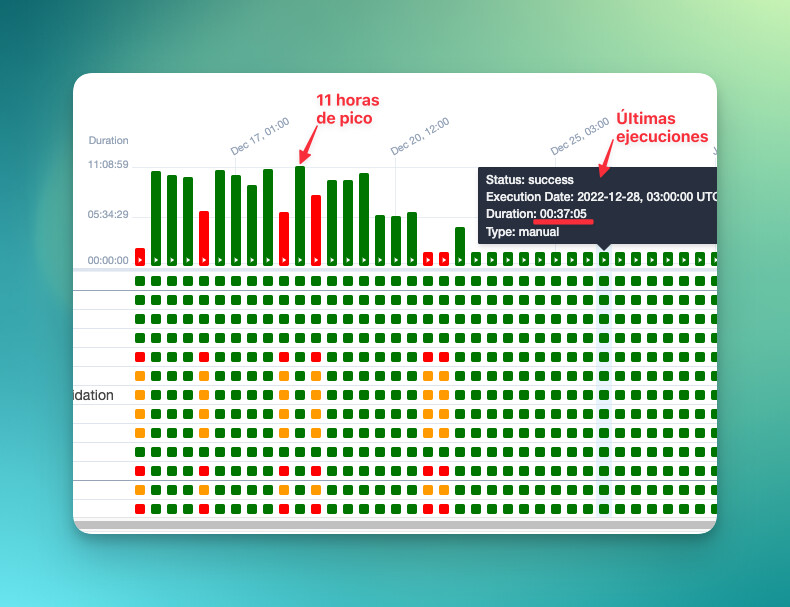
さらに興味があれば、このアプローチを前のプロセスにも拡張しました。改善された時間を示す表は以下の通りです:
改善前
| プロセス1 | プロセス2 | プロセス3 | 合計時間 | |
|---|---|---|---|---|
| プロバイダー A | 約20分 | 約8時間50分 | 約11時間 | 20時間10分 |
| プロバイダー B | 約20分 | 約3時間30分 | 約11時間 | 14時間50分 |
| プロバイダー C | 約10分 | 約7時間 | 約11時間 | 11時間17分 |
改善後
| プロセス1 | プロセス2 | プロセス3 | 合計時間 | |
|---|---|---|---|---|
| プロバイダー A | 約20分 | 約1時間 | 約1〜2時間 | 3時間20分 |
| プロバイダー B | 約20分 | 約45分 | 約1〜2時間 | 3時間5分 |
| プロバイダー C | 約10分 | 約7分 | 約1〜2時間 | 2時間17分 |
結局のところ、実行時間を節約できただけでなく、このプロセスを実行するKubernetesのPodやAWSマシンのリソースも節約できました。つまり、費用も削減されました。そしてよく言われるように、一枚の写真は千の言葉に勝ります。嵐が静まった様子を示す最後の写真はこちらです: