Python
Aprendiendo Python con Numpy y Pandas
Python Aprendizaje Pandas Numpy Blog
Introducción
Hace poco me interesé en aprender Python y siguiendo un tutorial he terminado con unos cuantos recursos que considero importantes tenerlos de cara al futuro:
Variables
num = 1+1-1*(1+1-1)/1+1*(-1)
type(1) # int
type(1.5) # float
type('hola') # str
type(True) # bool
mango = 10
manzana = 5 # Python infiere el tipo
aguacate = 15
print(aguacate + manzana + mango) # 30Listas
nombres_rrss = ['Facebook','Twitter','Instagram','Youtube','LinkedIn','WhatsApp']
print(nombres_rrss[0:3]) # Output ->['Facebook', 'Twitter', 'Instagram']
print(nombres_rrss[-2]) # Output ->LinkedIn
print(nombres_rrss[1]) # Output ->Twitter
nombres_rrss.append('Tuenti')
nombres_rrss.remove('Facebook')DataFrames
import pandas
fbk = ['Facebook', 2449, True]
twt = ['Twitter', 339, False]
ig = ['Instagram', 1000, True]
yt = ['Youtube', 2000, False]
lkn = ['LinkedIn', 663, False]
wsp = ['WhatsApp', 1600, True]
lista_rrss=[fbk, twt, ig, yt, lkn, wsp]
pandas.DataFrame(lista_rrss, columns=['Nombre','Cantidad','es_Facebook'])
df_vacio = pandas.DataFrame(columns = ['Nombre', 'Cantidad', 'es_FB', 'Año']) # DataFrame vacío
df_vacio = df_vacio.append({'Nombre': 'Facebook', 'Cantidad': 2449, 'es_FB': True, 'Año': 2006},ignore_index=True)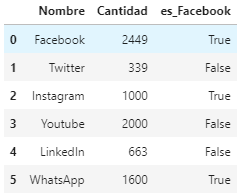
Numpy
import numpy
numeros_primos = [2,3,5,7,11,13,17,19,23,29]
array_primos = numpy.array(numeros_primos)
array_primos
# Output -> array([ 2, 3, 5, 7, 11, 13, 17, 19, 23, 29])
array_zeros = numpy.zeros(10)
array_zeros
# Output -> array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
array_numeros = numpy.arange(10)
array_numeros
# Output -> array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
array_pares = numpy.arange(0,20,2)
array_pares
# Output -> array([ 0, 2, 4, 6, 8, 10, 12, 14, 16, 18])
array_pares.reshape(2,5)
# Output -> array([[ 0, 2, 4, 6, 8],
# [10, 12, 14, 16, 18]])
array_impares = array_pares + 1
array_impares
# Output -> array([ 1, 3, 5, 7, 9, 11, 13, 15, 17, 19])
array_impares - array_pares # permite suma, resta, multiplicación...
# Output -> array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
array_primos.sum() # suma todos las posiciones 129
array_primos.mean() # media de todas las posiciones 12.9
array_primos.var() # varianza del array 73.28999999999999
array_fibonacci = numpy.array([55,0,144,1,21,89,5,8,13,1,34,3,2])
numpy.sort(array_fibonacci)
# Output -> array([ 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144]
numpy.sort(-array_fibonacci)
# Output -> array([-144, -89, -55, -34, -21, -13, -8, -5, -3, -2, -1, -1, 0])
A = numpy.arange(0,20,2).reshape(2,5)
A
# Output -> array([[ 0, 2, 4, 6, 8],
# [10, 12, 14, 16, 18]])
A[1,1] # 12
A[1,:] # array([10, 12, 14, 16, 18]) -> Selecciona solo una fila
A[:,1] # array([ 2, 12]) -> Selecciona solo una columna
array_fibonacci<20 # array([False, True, False, True, False, False, True, True, True, True, False, True, True])
array_fibonacci[array_fibonacci<20] # array([ 0, 1, 5, 8, 13, 1, 3, 2])
Pandas
import pandas
df_vacio = pandas.DataFrame(columns = ['Nombre', 'Cantidad', 'es_FB', 'Año'])
df_vacio = df_vacio.append({'Nombre': 'Facebook', 'Cantidad': 2449, 'es_FB': True, 'Año': 2006},ignore_index=True)
dataframe.loc[1, 'Nombre'] # 'Twitter'
dataframe.iloc[1,0] # 'Twitter'
dataframe['Nombre']
# output ->
# 0 Facebook
# 1 Twitter
# 2 Instagram
# 3 YouTube
# 4 LinkedIn
# 5 WhatsApp
# Name: Nombre, dtype: object
dataframe['Cantidad']>1500
dataframe[dataframe['Cantidad']>1500] # Devuelve DataFrame con aquellos campos que cumplan la condicion
dataframe.sort_values('Nombre', ascending=True ) # Devuelve DataFrame ordenado ascendentemente
dataframe.sort_values('Cantidad', ascending=False ) # Devuelve DataFrame ordenado descendentemente
dataframe.sort_values(['Año','Cantidad'], ascending=[True, False] ) # Devuelve DataFrame ordenando columnas y filasCSV
import pandas
finanzas = 'finanzas.xlsx'
pandas.read_csv('finanzas.csv')
dataframe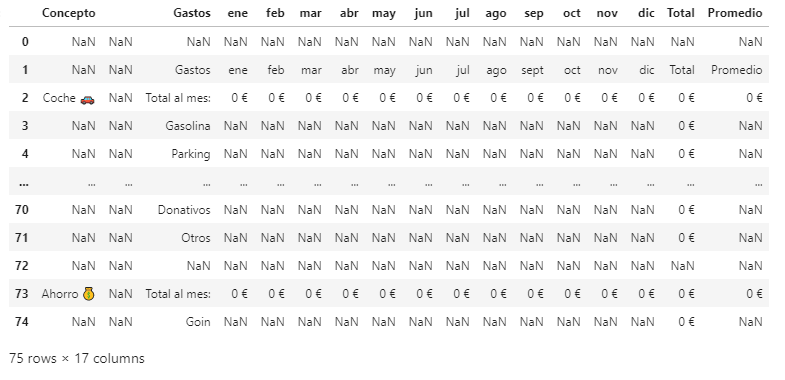
import pandas
dataframe = pandas.read_csv('finanzas.csv', header = None, names = ['Concepto', ' ','Gastos', 'ene', 'feb', 'mar', 'abr', 'may', 'jun', 'jul', 'ago', 'sep', 'oct', 'nov', 'dic', 'Total', 'Promedio'])
dataframe.iloc[2]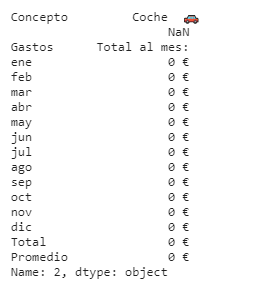
Comentarios
Cargando comentarios...